Primeros pasos en el SPSS
El programa de SPSS cuenta con 2 pestañas muy fáciles de utilizar:
- Editor de datos: Muestra todos los datos y variables con los que estamos trabajando. En él se puede modificar, añadir o eliminar datos o variables.
- Vista de resultados: Es la vista donde van a salir los resultados de nuestra investigación. Esta se puede guardar o exportar a otros formatos, como Word.
Dentro de la pestaña de editor de datos, cabe destacar que el programa tiene dos vistas, las cuales nos ayudan a organizar y trabajar con nuestros datos:
- Vista de datos: En ella se encuentran los datos de la investigación. Cada fila es una encuesta y cada columna define una variable (por ejemplo, una pregunta de la encuesta).
Vista de variables: En ella se encuentran las características y definición de cada variable con la que estamos trabajando.

Si entramos en la vista de variables, uno de los aspectos más importantes es definir el tipo de medida de las variables. Esta puede ser:
- Nominal: Sus valores ni son numéricos ni se pueden ordenar. Por ejemplo, en la pregunta “le resulta fiable la compra por Internet”, las respuestas posibles son “Si” y “No”, las cuales no son numéricas y tampoco implican ordenación. Otros ejemplos pueden ser: Estado Civil, Sexo, Ciudad…
- Ordinales: Los valores representan un orden, por ejemplo en la pregunta “¿Con qué frecuencia habitúa comprar productos textiles por Internet?” donde las respuestas son:
- Semanalmente
- Cada 15 días
- Una vez al mes
- Cada 6 meses
- No compro
Como podemos observar, las respuestas llevan consigo un orden específico. Otro ejemplo puede ser la valoración o el nivel de satisfacción de un determinado producto.
- Escala: Son las representadas por un número. Un claro ejemplo de esto es la Edad, donde cada encuestado responde con un valor numérico.
Diferencia entre análisis univariante y bivariante
Este es un análisis estadístico donde solo una variable está involucrada. Para entenderlo mejor, en el ejemplo de la tienda de ropa online, un posible análisis univariante sería:
- ¿Ha comprado alguna vez por internet?
- ¿Le resulta fiable la compra por internet?
- ¿Con qué frecuencia habitúa a comprar productos textiles por Internet?
Como podemos observar, solo un factor está involucrado en estos análisis: Si compra alguna vez por internet, si esta compra le resulta fiable y con qué frecuencia compra productos textiles.
Definir bien las variables en los análisis univariantes, nos ayudará a sacar los resultados estadísticos correctos. Ya que dependiendo de cómo las cataloguemos, tendremos que realizar unas acciones u otras en el programa. Lo vemos en el siguiente cuadro.
Tabla 1: Escala de medidas
| Escala de medida | Frecuencias | Medidas de posición | Medidas de dispersión | Medidas de distribución | Gráficos |
| Nominal | Si | Moda | No | No | Sectores y barras |
| Ordinal | Si | Moda | No | No | Sectores, Barras Área |
| Escala | No | Media, Mediana y Moda | Si | Si | Histograma, Áreas dispersión |
2.1.1. Variables Nominales:
En este supuesto, los estadísticos que tendremos que utilizar son la moda, la frecuencia y el gráfico de barras. Para conseguir estos análisis los pasos que debemos seguir son:
Menú de arriba – Analizar – Estadísticos descriptivos – Frecuencias
Una vez en la pantalla emergente, seleccionaremos los estadísticos mencionados arriba y… ¡Ya está! Tu primer análisis conseguido, ¿No parece tan difícil no?
A continuación, veremos un ejemplo de posible comentario, con el caso del E-commerce de camisetas.
- ¿Has comprado alguna vez por internet?

Los estadísticos muestras que existen 93 observaciones, todas ellas válidas; puesto que existe un número de perdidos, mostrando la moda, entiendo por tal el estadístico que muestra el valor más frecuente, como el 1; o bien en la interpretación de los datos, el “Sí”.
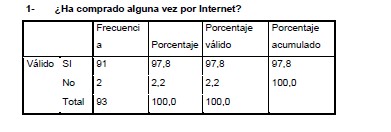
Teniendo en cuenta lo anterior y en vistas de que la información nos es fiable por su elevado número de frecuencia de 91, con un porcentaje realmente elevado del conjunto.
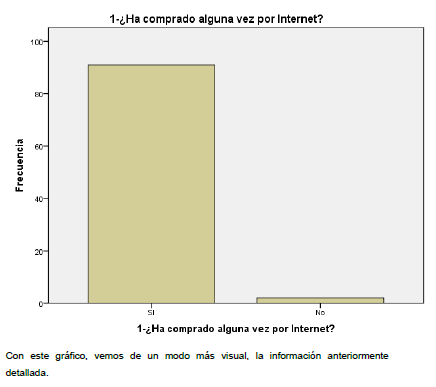
2.1.2.Variables ordinales
Como vimos en el cuadro anterior, para este tipo de escalas tendremos que obtener los estadísticos de mediana, cuartiles e Histograma. Este tipo de escalas, se obtienen de manera parecida a las variables nominales, teniendo únicamente que seleccionar el estadístico de mediana a mayores. A continuación, veremos este supuesto en el ejemplo del E-commerce.
- ¿Con qué frecuencia habitúa comprar productos textiles por Internet?

Observamos que los valores fiables a diferencia con las anteriores variables, son más bajos en referencias relativas; viendo que existen 24 valores perdidos, del mismo modo que vemos que la mediana que es valor que arroja tantos valores a su izquierda como a su derecha; nos muestra el valor 4; siendo este el mismo que la moda e interpretándose como “Una vez al mes”.


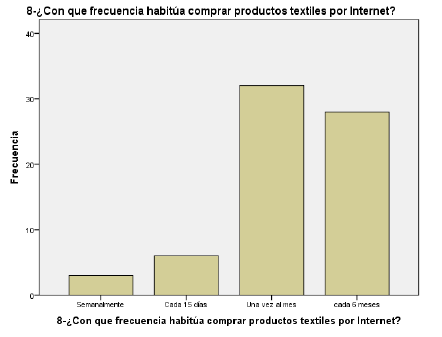
En estas variables, el proceso para obtener los estadísticos es un poco diferente, pero igual de sencillo. Lo vemos a continuación:
Menú de arriba – Analizar – Estadísticos descriptivos – Descriptivos
Una vez dentro de esta pestaña, seleccionaremos los estadísticos que queremos obtener, los antes mencionados en el cuadro. El análisis que deberías hacer sería algo parecido a este:
- Edad


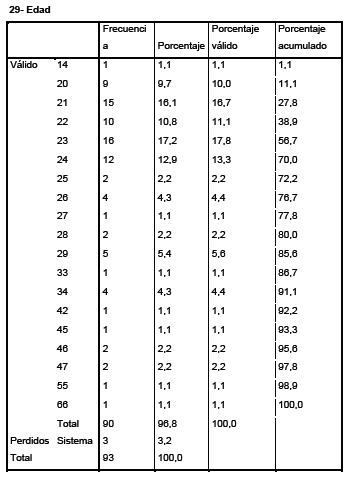

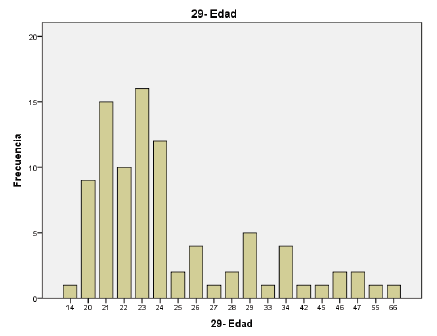
En los análisis bivariante, donde vamos a ver la correlación o grado de dependencia de dos variables conjuntamente, Para esto, es preciso definir las hipótesis que vamos a trabajar antes de empezar a estudiar los estadísticos que sacamos con SPSS:
H0: Rechazamos la hipótesis principal
H1: Aceptamos la hipótesis principal
Ejemplo:
H0: Las variables “Compra por internet” y “Edad” no están relacionadas
H1: Las variables “Compra por internet” y “Edad” son dependientes
Después de definir las hipótesis que queremos rechazar, definiremos los tipos de estadísticos que vamos a obtener dependiendo de qué tipo de variables estemos comparando:
Tabla 2: Relaciones de variables
| Independiente | Dependiente | Estadístico |
| Escala NO métrica | Escala NO métrica | Tablas cruzadas |
| Escala No métrica | Escala métrica | ANOVA de un factor |
| Escala métrica | Escala métrica | Correlación lineal |
Para obtener este descriptivo, tendremos que seguir estos pasos en SPSS:
Menú de arriba – Analizar – Estadísticos descriptivos – Tablas de contingencia
Una vez en esta pantalla, seleccionaremos en la fila la variable dependiente y en columna la independiente. Dentro de “estadísticos” seleccionaremos la casilla de Chi-cuadrado y dentro de “Casillas” seleccionaremos mostrar los porcentajes en columna. A continuación, estudiaremos un ejemplo.
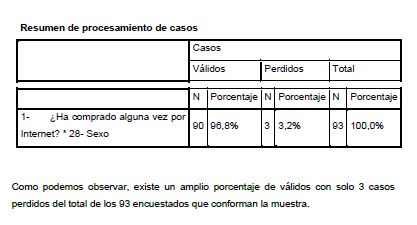
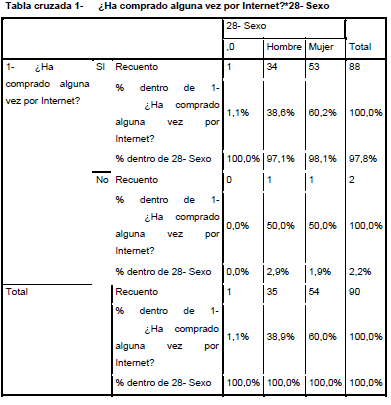
Si interpretamos por columnas. podemos decir que un 97,8% del total de la muestra compra por intemet, y dentro de este et 97,1% del total de hombres también lo hace. mientras tan solo el 2,9% no. Casi similar es el caso de las mujeres, en cuyo caso el 98,1% del total de mujeres compra por internet mientras tan solo el 1,9%no lo hace.
Por lo tanto, en términos absolutos, de un total de 35 hombres, 34 compran por intenet y tan solo 1 no lo hace; Caso similar al de las mujeres, en el que de un total de 54 mujeres, 53 compran y 1 no lo hace. Todo esto conforma un total de 90 personas encuestadas, de las que 88 compran y 2 no lo hacen.
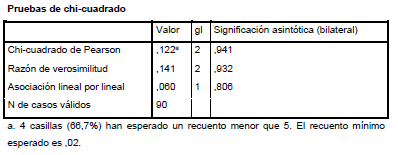
No podemos aceptar ni rechazar la hipótesis Nula, ya que el porcentaje que aparece debajo de la tabla debe ser menor o igual al 20% para poder sacar conclusiones veraces. En el caso de que así fuera, aceptaríamos la hipótesis nula al ser P mayor que el nivel de significación del 5%.
Para obtener este descriptivo, tendremos que seguir estos pasos en SPSS:
Menú de arriba – Analizar – Comparar medias – ANOVA de un factor
Una vez en esta pantalla, seleccionaremos en la lista de dependientes nuestra variable dependiente y en factor la independiente. Dentro de “contrastes” seleccionaremos la casilla de descriptivos y el gráfico de las medias. A continuación, lo ejemplificaremos con el caso antes mencionado del E-commerce.

Como podemos observar, P=0,99 es mayor que el nivel de significación por lo que aceptamos la hipótesis Nula, por lo que decimos que la compra por internet y la edad son dos variables que no están relacionadas. Si el valor fuera inferior al nivel de significación 0,05%, rechazaríamos Ho, por lo que tendríamos que mirar la media cuadrática con la finalidad de determinar posibles variaciones inter-grupo e intra-grupo.
En este sentido, encontramos pequeñas variaciones tanto entre opiniones de grupos distintos como en variaciones dentro del mismo grupo.
3.2.3. Correlación lineal
Para obtener este descriptivo, tendremos que seguir estos pasos en SPSS:
Menú de arriba – Analizar – Correlaciones – Bivariadas
Como llevamos haciendo a lo largo del post, mejor lo ejemplificamos con nuestro caso:
H0: Las variables “Ingresos” y “Precio de camiseta” no están relacionadas
H1: Las variables “Ingresos” y “Precio de camiseta” son dependientes.

Comparamos la P con el nivel de significación; en este caso es 0,141 por lo tanto mayor a 0,05; es por eso que aceptamos la hipótesis nula, con una probabilidad de equivocarnos del 5%, de tal modo que no existe relación entre las dos variables.
En este caso la correlación de Pearson, muestra un valor de 0,177 de tal modo que si una variable aumenta, la otra aumenta, es por eso que la correlación de Pearson, nos dice que a más de ingresos, más están dispuestos a pagar por la camiseta y viceversa.
Existe una relación débil, puesto que el valor se acerca a 0, entonces, si una cuenta aumenta, la otra aumenta también aunque de manera muy poco significativa.
4. Otras funcionalidades que nos ayudarán en el trabajo
- Recodificación: Permite recodificar los valores de una determinada variable en otros valores. Esto puede ser útil para agrupar una gran cantidad de valores de una variable.
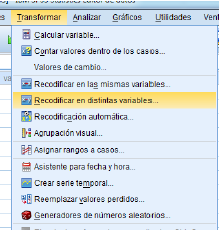
- Transformación: Mediante la transformación numérica de variables, permite crear otras nuevas. Por ejemplo para sumar determinados valores de la variable.

- Filtrar: Permite estudiar casos de una submuestra. Por ejemplo, estudiar la opinión acerca de un determinado producto de solo los hombres que conforman nuestra muestra.
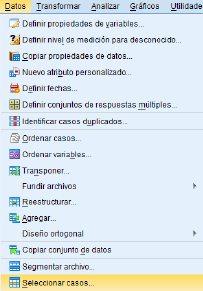
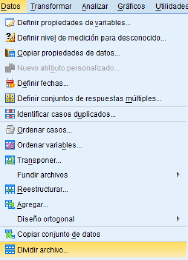
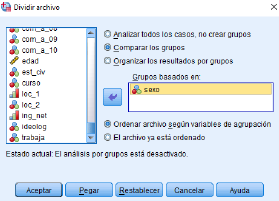
- Dividir: Permite seleccionar determinados grupos de submuestras, para analizarlos por separada o para su posterior comparación con otros casos.
- Comparación:
- Análisis por separado:
Autor: Diego Graña Parga